A rag knowledge base serves as the backbone of Retrieval Augmented Generation systems. It stores and organizes external data, enabling RAG models to retrieve relevant information and generate accurate outputs. Unlike traditional databases, it focuses on enhancing the factual accuracy of language models by providing context-specific knowledge. This makes it essential for tasks like customer service, marketing, and enterprise knowledge management. By integrating a well-structured knowledge base, you can ensure your RAG system delivers precise, coherent, and up-to-date responses, transforming how you access and utilize information.In the past ten years, ai knowledge base Defeated many competitors, courageously advanced in the struggle, and polished many good products for customers. https://www.puppyagent.com/
Basics of Knowledge Bases in RAG
knowledge base
Image Source: Pexels
What is a rag knowledge base, and why is it essential for RAG?
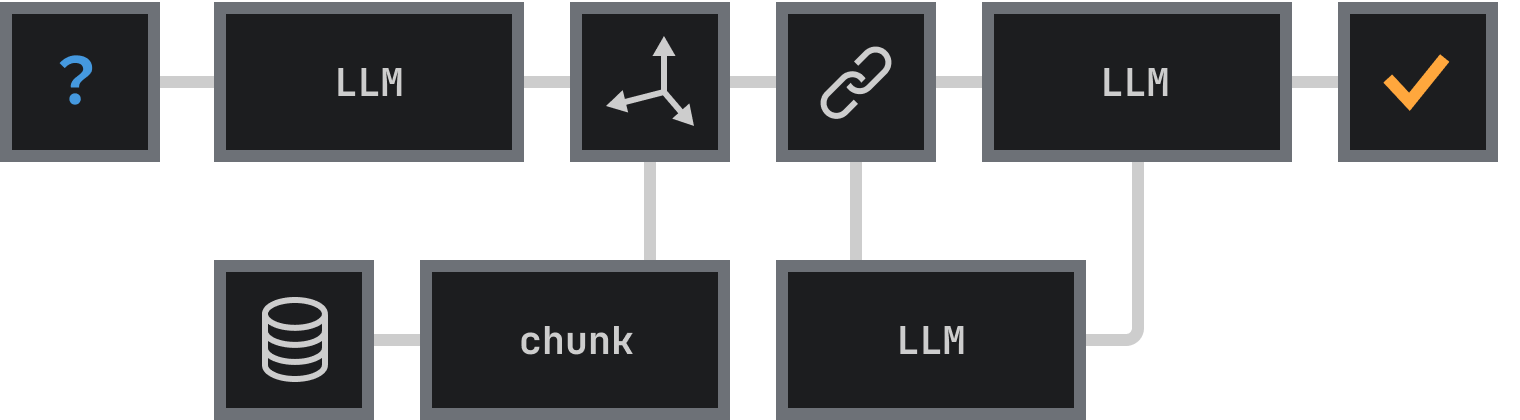
A rag knowledge base acts as the foundation for Retrieval-Augmented Generation systems, also known as rag LLM systems. It serves as a centralized repository where external data is stored and organized. This structure allows RAG models to retrieve relevant information efficiently. Unlike traditional databases, which often focus on storing structured data for transactional purposes, a rag knowledge base emphasizes flexibility. It handles unstructured data like documents, articles, or even multimedia files, making it ideal for knowledge-intensive tasks.
Why is this important? Because RAG systems rely on accurate and context-specific information to generate outputs. Without a well-constructed knowledge base, the system might produce irrelevant or incorrect responses. By integrating a rag knowledge base, you ensure that your RAG model has access to the right data at the right time, enhancing both accuracy and user experience. This is crucial for understanding how does rag work and its effectiveness in various applications.
How does a rag knowledge base differ from traditional databases?
A RAG knowledge base serves a distinct purpose compared to traditional databases. Traditional databases specialize in structured data like spreadsheets and are used for tasks like inventory or financial management. In contrast, a RAG knowledge base focuses on unstructured or semi-structured data such as documents, PDFs, and web pages. Unlike databases that support predefined queries, a RAG knowledge base retrieves data dynamically to meet RAG model requirements. This adaptability ensures accurate, context-aware outputs, making it an essential tool for applications like customer support that demand personalized responses.
Building and Managing a Knowledge Base for RAG
manage knowledge base
Image Source: Unsplash
Creating and managing a rag knowledge base requires careful planning and the right tools. This section will guide you through the essential steps, technologies, and strategies to ensure your knowledge base is effective and reliable for retrieval augmented generation.
Steps to Create a Knowledge Base
Identifying relevant data sources
The first step in building a rag knowledge base is identifying where your data will come from. You need to focus on sources that are accurate, up-to-date, and relevant to your use case. These could include internal documents, customer support logs, product manuals, or even publicly available resources like research papers and websites. The goal is to gather information that your RAG system can use to generate meaningful and precise outputs.
To make this process easier, start by listing all the potential data sources your organization already has. Then, evaluate each source for its reliability and relevance. By doing this, you ensure that your knowledge base contains only high-quality information, which is crucial for effective text generation and minimizing hallucinations in generative AI systems.
Organizing and structuring the data for retrieval
Once you’ve identified your data sources, the next step is organizing the information. A well-structured rag knowledge base allows for faster and more accurate retrieval. Begin by categorizing the data into logical groups. For example, you could organize it by topic, date, or type of content.
After categorizing, structure the data in a way that makes it easy for retrieval systems to access. This might involve converting unstructured data, like PDFs or text files, into a format that supports efficient querying. Tools like Elasticsearch can help you index and search through large volumes of textual data, making retrieval seamless.
Tools and Technologies for Knowledge Base Management
Popular tools for storing and retrieving data
When it comes to managing your rag knowledge base, choosing the right tools is crucial. Elasticsearch is a powerful option for storing and retrieving textual data. It’s a distributed search engine that excels at handling large datasets and delivering fast search results. If your knowledge base relies heavily on text, Elasticsearch can be a game-changer.
For applications requiring vector-based retrieval, Pinecone is an excellent choice. Pinecone specializes in similarity search, which is essential for finding contextually relevant information. Its hybrid search functionality combines semantic understanding with keyword matching, ensuring precise results. This makes it ideal for RAG systems that need to retrieve nuanced and context-specific data.
AI-powered tools for automating knowledge base updates
Keeping your knowledge base up-to-date can be challenging, but AI-powered tools simplify this task. These tools can automatically scan your data sources for new information and update the knowledge base without manual intervention. This ensures that your RAG system always has access to the latest and most relevant data.
For instance, some platforms integrate machine learning algorithms to identify outdated or irrelevant entries in your knowledge base. By automating updates, you save time and reduce the risk of errors, making your system more efficient. This is particularly important for maintaining the accuracy of LLM knowledge bases, which rely on up-to-date information for generating reliable responses.
Ensuring Data Quality and Relevance
Techniques for cleaning and validating data
Data quality is critical for the success of your rag knowledge base. Cleaning and validating your data ensures that the information is accurate and free from errors. Start by removing duplicate entries and correcting inconsistencies. You can also use automated tools to detect and fix issues like missing fields or formatting errors.
Validation is equally important. Cross-check your data against trusted sources to confirm its accuracy. This step minimizes the chances of your RAG system generating incorrect or misleading outputs. Implementing proper citations and references within your knowledge base can also help maintain data integrity and provide a trail for fact-checking.
Strategies for maintaining relevance over time
A rag knowledge base must stay relevant to remain effective. Regularly review your data to ensure it aligns with current needs and trends. Remove outdated information and replace it with updated content. For example, if your knowledge base includes product details, make sure it reflects the latest versions and features.
Another strategy is to monitor user interactions with your RAG system. Analyze the types of queries users submit and identify gaps in your knowledge base. By addressing these gaps, you can continuously improve the system’s performance and relevance.
A well-structured knowledge base is the heart of any effective RAG system. It ensures your system retrieves accurate, relevant, and up-to-date information, transforming how you interact with data. By focusing on quality and organization, you can unlock the full potential of RAG technology.
Integrating RAG architecture into a knowledge base can transform how users interact with information, making data retrieval faster and more intuitive.
With PuppyAgent, you gain tools to optimize your knowledge base effortlessly, empowering your business to achieve maximum efficiency and deliver exceptional results in the realm of generative AI and natural language processing.